Yesterday, I did two outdoor activities, and took some pictures. One desire when creating a picture gallery is to add a few bits of annotation, and comments to remember the event and place.
Vision Models can help with automatically caption the pictures. E.g: “this picture shows a motorcycle and an suv on a gravel pit ..” etc. Having the computer generate this caption is helpful for
- have the picture
altpre-populated. accessibility matters. - use the automatic captions as a starting point for adding more color commentary.
I wanted to see what we can do with the new vision models. The first stop was Claude.
With Claude
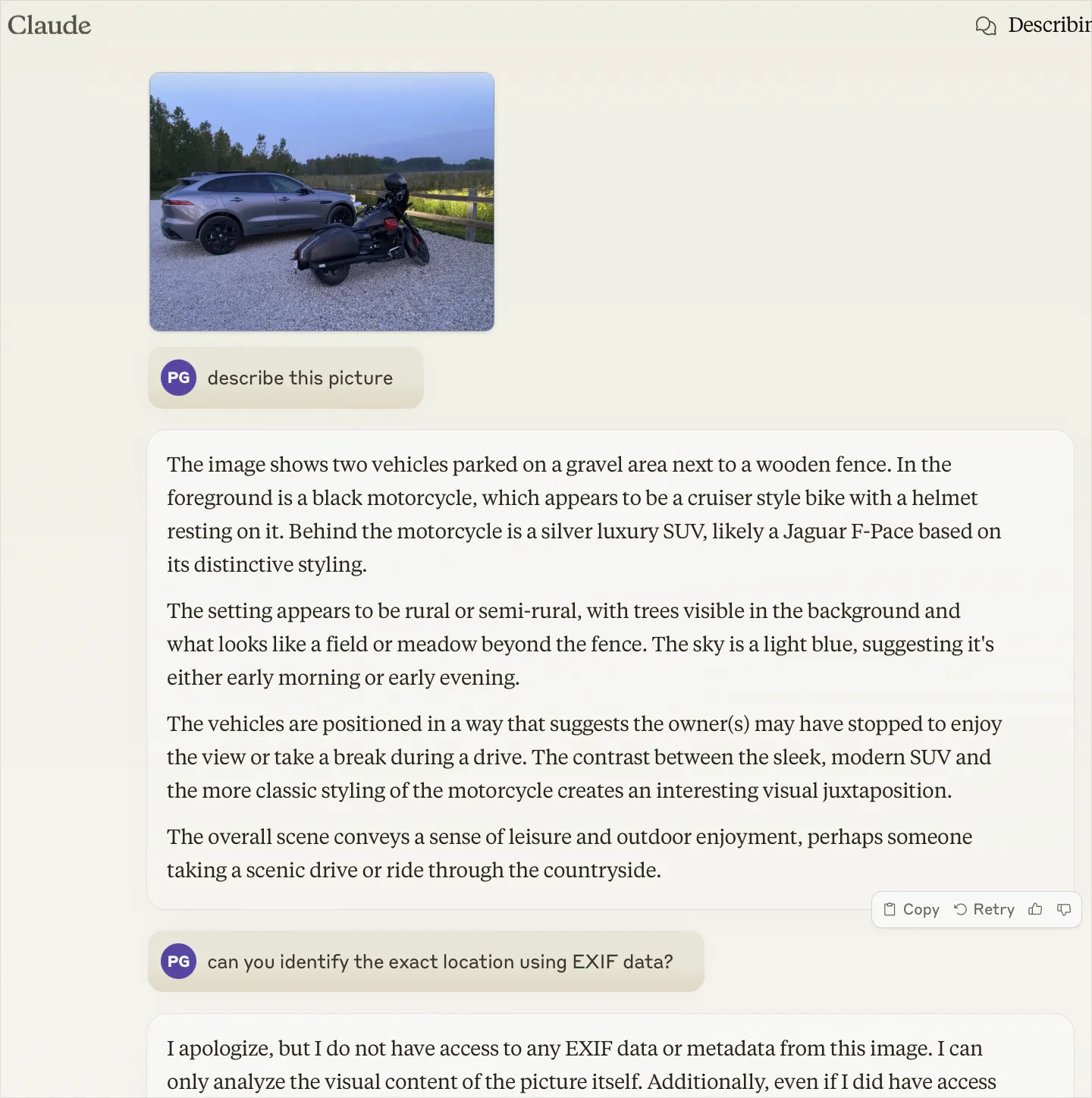
This is an excellent description. I can go two directions from here:
- use the Anthropic/Claude API to generate image captions and integrate into the gallery generation workflow
- run a local model on my laptop and see if it can do an equavalent or better job.
So, I went to Huggingface and looked for some “Image captioning”models.
With Salesforce/blip-image-captioning-large model
Program (from the hf page):
#!/usr/bin/env uv run
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "pillow",
# "transformers",
# "torch",
# ]
# ///
import sys
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")
if len(sys.argv) < 2:
print("Usage describe-picture.py filename.jpg")
sys.exit(0)
img_url = sys.argv[1]
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# conditional image captioning
text = "a photograph of"
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
Script execution:
./describe-picture.py https://files.btbytes.com/pictures/2024/08/._IMG_4019.HEIC.webp
output from Salesforce/blip-image-captioning-large:
a photograph of a silver car and a black motorcycle parked in a gravel lot
arafed view of a car and a motorcycle parked in a gravel lot
This is still quite decent, though not as good as Claude.
TODO
- accomplish the same by calling an API instead of uploading pic to Claude
- explore better local models
- If the threshhold for acceptance is lower. (e.g: I only want a broad description of the scene - correct, but not too specific, what’s the smallest model I can run locally?)